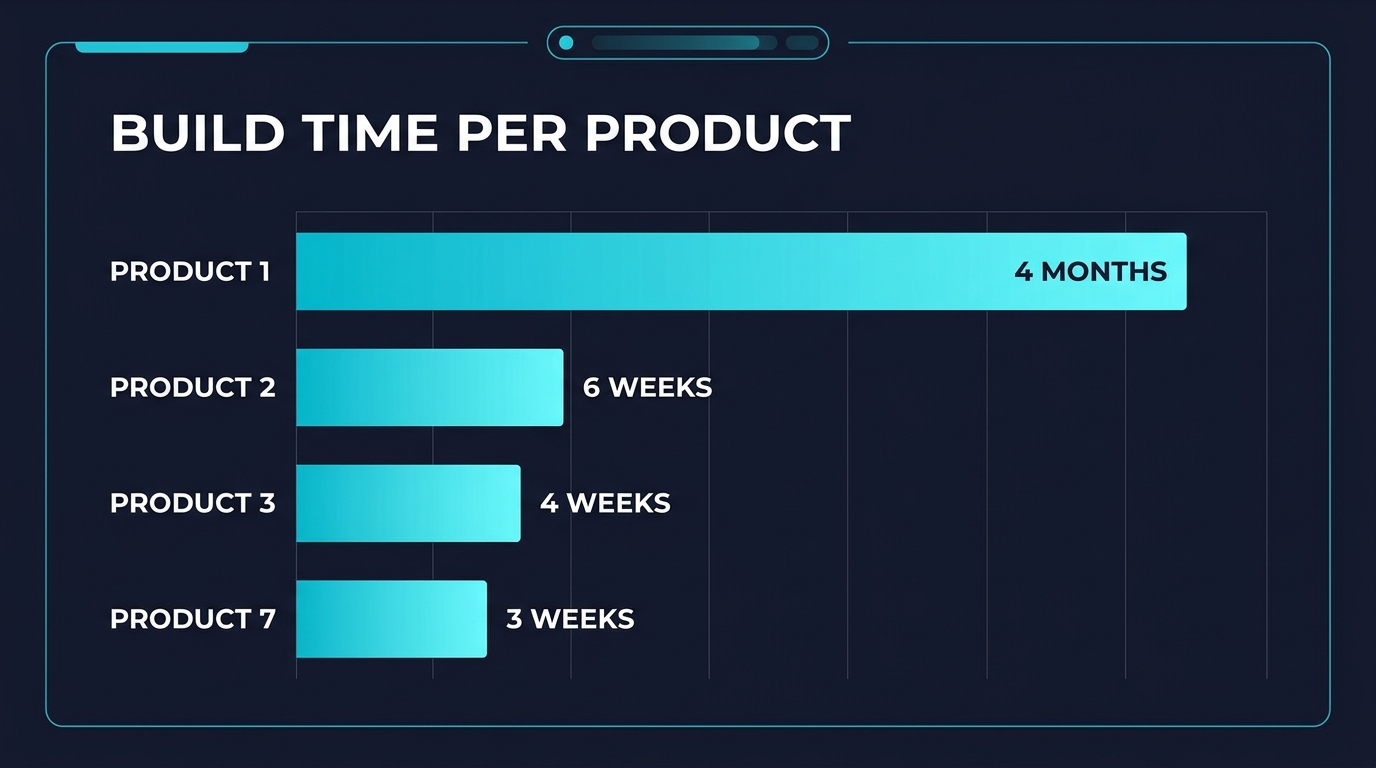
My first product took 4 months.
The seventh took 3 weeks.
Same developer. Same complexity. Same quality bar. Same number of features, same testing standards, same deployment pipeline.
The only thing that changed was what I was building on top of.
And that difference is the only thing that matters.
Most engineers are stuck in a loop
Here's what I see when I look at how most developers work:
They start a new project. They set up a database. They configure testing. They make decisions about deployment. They write documentation standards. They build authentication. They wire up monitoring.
Then they build the actual product.
Six months later, they start another project. They set up a database. They configure testing. They make decisions about deployment...
The same decisions. The same setup. The same two weeks of boilerplate before anything real gets built.
Nobody talks about this. It's invisible. It doesn't show up in sprint planning or roadmap reviews. But it's there every single time, eating weeks you could be spending on the thing that actually matters.
I watched myself do this three times before I stopped and asked a question that changed everything.
What if every project I build makes the next one faster?
Not theoretically. Not "in spirit." Mechanically. Measurably. In a way where the fourth product literally takes half the time of the first, and the seventh takes a quarter.
That's compound engineering.
It's the same principle as compound interest, applied to building software. And just like compound interest, almost nobody does it because the upfront cost is invisible and the payoff is delayed.
The two months nobody would have funded
I need to be honest about how this started.
My first two months were almost entirely infrastructure.
No features. No products. No launches. No demos. Nothing I could show an investor, a client, or a Twitter audience. Just a developer sitting in a terminal, building things that would never be seen by a user.
Shared database configuration. A port registry so no two services collide. A Docker compose file that runs one Postgres container and one Redis instance for every project I'll ever build. Agent definitions. A skill system. Documentation standards. A single root configuration file that every future project would inherit.
It looked like zero progress.
It felt like zero progress.
If you're the kind of person who needs to ship something every week to feel like you're moving, this phase will break you. I know because it almost broke me. There were mornings where I opened my laptop, stared at infrastructure code, and genuinely wondered if I was wasting my time.
I wasn't.
But I didn't know that yet.
Then the curve bent
Product #1 took 4 months. That's because I was building the infrastructure and the product at the same time. Every pattern was new. Every decision was from scratch. Every bug fix was a first encounter.
Product #2 took 6 weeks. The infrastructure already existed. I just built the product.
Product #3 took 4 weeks. I reused patterns from the first two. Agent memory, testing conventions, deployment scripts. All in place. All proven.
Product #4 took 3 weeks.
Product #7 took 3 weeks.
Read that again. Products 4 through 7 all took roughly the same time. But each one was more complex than the last. The time didn't increase because the foundation absorbed the complexity.
That's the part nobody understands until they see it.
The curve doesn't flatten. It steepens.
Every product I build makes the next one faster. And every improvement I make to the shared layer retroactively improves every product that's already running.
This is compounding. Not as a metaphor. As a mechanical fact.
What's actually under the hood
Let me show you what nobody sees.
Right now, underneath all 7 of my AI products, there is:
One Postgres container running 16 databases.
One Redis instance handling caching, queues, and sessions across everything.
122 AI agents. Each one has a defined role, a memory file that persists across sessions, and a work log that tracks what it's done.
48 shared skills. Video recording, web scraping, browser automation, image generation, deployment, testing. Any project can use any skill.
72 shared documentation files. Standards, patterns, playbooks. Written once, inherited everywhere.
And one root configuration file that every single project reads on startup.
Total monthly infrastructure cost for all of this: about $4.
That number sounds absurd. It's not. It's the natural result of sharing instead of duplicating.
Shared infrastructure is cheap. Duplication is what's expensive.
When you run 7 separate Postgres instances, you pay 7 times. When you run one container with 7 databases, you pay once. When you write testing standards 7 times, you maintain 7 versions. When you write them once and every project inherits them, you maintain one.
The math is obvious when you write it out. Almost nobody does it.

How compounding actually works in practice
Let me be specific, because "compounding" is one of those words that sounds profound and means nothing unless you ground it.
One investment, seven returns. When I fix a bug in the testing framework, all 7 projects get the fix. I don't open 7 repos. I don't make 7 pull requests. I fix it once, in the shared layer, and it propagates.
When I write a new automation skill for one product's demos, it immediately works for every other product. When I improve how agents store and retrieve memory, that improvement shows up everywhere the next time an agent runs.
This isn't clever architecture. It's the decision to stop treating every project like it exists in isolation.
Here's what that looked like this quarter:
Over 1,000 commits across the portfolio. 400+ tracked features shipped. 311,000+ lines of TypeScript across just the top 3 projects.
Every one of those 72 shared documentation files was written because one project needed it. But every project after that got it for free.
That's the compounding. Not in the output. In the input. The same amount of effort produces more results every single time.
Three stories from the last month
I want to tell you about three specific moments where compounding showed up in a way I could feel.
The agent memory problem.
I needed AI agents to remember things across sessions. Not conversation memory that evaporates when the window closes. Persistent memory. Files on disk that survive restarts, context switches, and days between sessions.
The first time I solved this, it took two weeks. I tried four different approaches. I broke things. I rebuilt things. I tested edge cases I didn't know existed. By the end, I had a pattern that worked.
When the third project needed agent memory, it took an afternoon. I dropped in the template, adjusted the paths, and it worked.
When the seventh project needed it, I didn't even think about it. The infrastructure set it up automatically. New project, memory pattern in place, zero configuration.
Two weeks of work, paying dividends across 7 products. And it will keep paying for every product after that. And the one after that.
The testing standard.
Playwright for end-to-end testing. Vitest for unit tests. A shared runner script. A naming convention. An organization pattern. A set of expectations about how tests are written, where they live, and how they run.
I built this once, in the shared infrastructure repo. Every project inherits it.
No project reinvents how testing works. No developer wastes a day figuring out "how do we run tests here?" No one debates naming conventions or folder structures. Those decisions were made once, and they propagate everywhere.
When I improve the test runner, every project improves.
When I add a new testing utility, every project can use it immediately.
This is what infrastructure is supposed to do. Make decisions once so you never have to make them again.
The skill system.
48 skills organized into packs. Core skills load everywhere. Dev skills activate in code-heavy projects. Marketing skills activate for growth work.
I built a video recording skill because I needed to demo FairStack. The skill captures browser interactions, generates recordings, saves them to a standard location.
The moment it was built, it worked for JamWise. And Noted. And Forge. And Memorable. And everything else.
I didn't configure it for those projects. I didn't copy files. I didn't even think about it. The skill system distributed it automatically.
This is the part most people miss.
Compound engineering isn't about being smart. It's not about writing elegant code or having a 200 IQ architecture vision.
It's about building things once and letting the system do the multiplication.
The multiplication is the whole point. Everything else is just disciplined setup.
Why almost nobody does this
I've thought about this a lot.
The answer is simple, and it's not technical. It's psychological.
Compounding requires you to invest before you see returns. In finance, that means putting money into an index fund and not touching it for 10 years. In engineering, it means spending two months on infrastructure that produces zero visible output.
Most people can't do this.
Not because they're lazy. Not because they're bad engineers. Because the feedback loop is broken during the setup phase.
You open your laptop. You write infrastructure code. You close your laptop. Nothing shipped. No one noticed. No metric moved.
Day after day after day.
Every instinct tells you to stop and build something real. Something you can show someone. Something that feels like progress.
The people who power through that phase are rare. Not because it's heroic. Because most people trust the feeling over the math.
I trusted the math. It paid back everything and then some.
The honest downsides
I'm not going to pretend this is all upside. Compounding in engineering has real costs.
Coupling.
One Postgres container means one failure point. If Docker goes down, everything goes down. Not one product. All of them.
In development, that's a minor inconvenience. You restart Docker. In production, each product gets its own hosting. But in the early stages, when everything runs on one machine, the coupling is real. You feel it the first time Docker crashes and seven products stop responding simultaneously.
Complexity debt.
72 documents and 48 skills means 72 documents and 48 skills to maintain. When a standard changes, it propagates everywhere.
That's great when the change is correct.
It's a problem when you push something broken across 7 projects at the same time. One bad change to a shared standard doesn't break one thing. It breaks everything that depends on it.
The patience tax.
Two months of infrastructure with nothing to show for it is psychologically expensive. I've already said this. I'll say it again because it's the reason most people will read this post, nod their heads, and never do it.
The patience tax is real. You pay it upfront. You pay it alone. And you pay it without any guarantee it works.
Until it does. And then you never pay it again.
If you're building more than one thing
If you're building multiple products, or even thinking about it, here's the infrastructure worth sharing from day one.
Database.
One container, separate databases per project. Not separate servers. Not separate cloud instances. One Postgres container with a database per project. Total cost: pennies.
Configuration.
One root config file that every project inherits. Port assignments, environment variables, git conventions. Write it once. Every project reads it on startup.
Testing.
Write the standards once. Every project follows them. Don't let each project invent its own testing approach. That's how you end up with 7 projects and 7 different ways to run tests.
Documentation.
Standards, patterns, playbooks. If you're explaining something twice, write it down once and point everything at it. The second time you explain something is the last time. From that point on, it's a link.
Tooling.
Anything you build that isn't specific to one product belongs in the shared layer. Scripts, utilities, automation, CI pipelines. If two projects could use it, it lives in the shared repo.
The test is simple.
Does building product N+1 take less time than product N?
If yes, your engineering is compounding.
If no, you're just building N separate things that happen to share an owner.
The deeper point
I started this post with a timeline. 4 months to 3 weeks. But the timeline isn't really the point.
The point is that most engineers think linearly. They think each project is independent. They think the work they did on the last product is "done" and has nothing to offer the next one.
That mindset is leaving years on the table.
Every problem you solve should make the next problem easier. Every pattern you discover should propagate. Every tool you build should multiply.
If your engineering isn't compounding, you're working harder than you need to. And you'll keep working that hard forever.
I'm documenting the full system publicly. Not the code. The patterns. The decisions. The architecture choices that made compounding possible.
More coming on how 122 AI agents coordinate across projects. How the skill system loads the right tools at the right time. Why a single Postgres container for 16 databases is the right call at this stage. And the real cost of running 7 AI products as one person.
Build notes from someone doing this in production. Nothing theoretical.